LLM à diffusion : et si l'IA devenait meilleure en relecture qu'en rédaction ?
Modèles de diffusion, DiffusionGemma, et une intuition à rebours du discours ambiant : la prochaine rupture des LLM n'est peut-être pas un modèle qui écrit mieux, mais un modèle qui corrige mieux.
De quoi parle-t-on ?
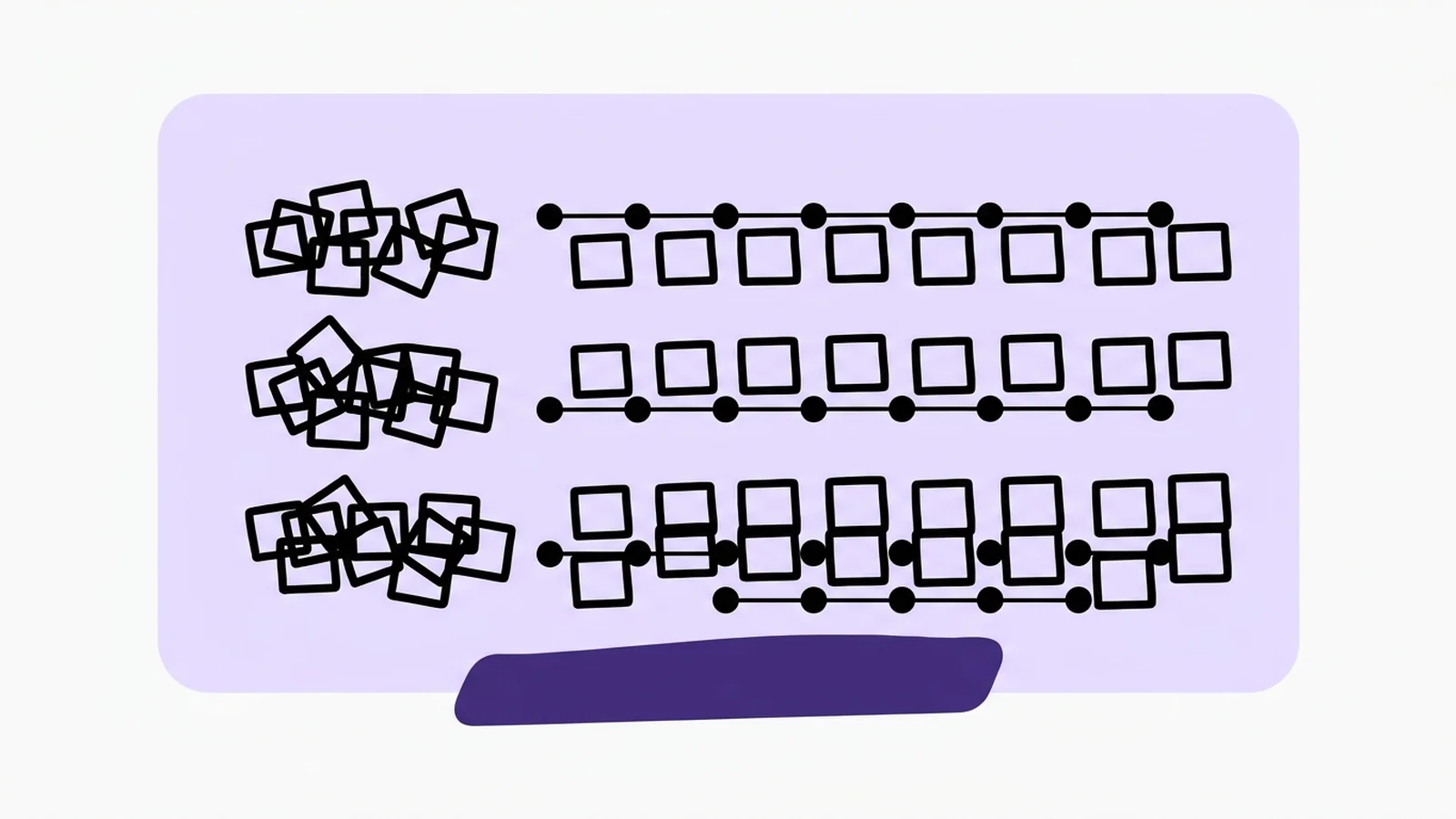
Depuis ChatGPT, les grands modèles de langage partagent le même réflexe : ils écrivent un mot après l'autre, de gauche à droite. On appelle cela l'autorégression. Le modèle lit ce qui précède, prédit le token suivant, l'ajoute, recommence. Comme une machine à écrire : une fois la touche frappée, la lettre est sur le papier, et l'on ne revient pas en arrière.
En juin 2026, Google DeepMind a publié DiffusionGemma, un modèle ouvert (licence Apache 2.0) qui fonctionne sur un principe différent : la diffusion. C'est la famille de techniques derrière les générateurs d'images comme DALL·E, Midjourney ou Stable Diffusion. Appliquée au texte, l'idée tient en une phrase : au lieu d'écrire mot à mot, le modèle part d'un brouillon entièrement « bruité » et le raffine en plusieurs passes, en travaillant sur tout le bloc à la fois.
La métaphore de Google résume l'écart : on passe d'une machine à écrire séquentielle à une presse d'imprimerie qui tamponne tout le bloc d'un coup.
DiffusionGemma travaille sur un « canvas » de 256 tokens. Il part d'un bloc aléatoire et fait quelques allers-retours pour le nettoyer, en validant 15 à 20 tokens à chaque passe. Google annonce jusqu'à 4 fois plus de tokens par seconde qu'un modèle classique sur un GPU dédié, soit plus de 1000 tokens par seconde sur une carte H100.
Deux propriétés en découlent.
- L'attention est bidirectionnelle. Chaque mot voit tous les autres, y compris ceux qui le suivent. Un modèle classique ne voit que le passé.
- Le texte reste modifiable jusqu'au bout. Tant que le raffinement continue, n'importe quel mot peut encore changer, et le modèle corrige ses propres erreurs en cours de route.
Pourquoi c'est intéressant : réviser plutôt qu'écrire
Pendant des années, on a entraîné les modèles à continuer un texte : prédire la suite, encore et encore. Or une grande partie du travail utile sur du texte n'est pas de la continuation, c'est de la révision.
Reformuler un paragraphe. Combler un trou au milieu d'un document. Corriger un bug dans une fonction sans réécrire le fichier. Refactorer du code existant. Ces tâches ne s'écrivent pas de gauche à droite : ce sont des tâches d'édition, où il faut voir l'ensemble et modifier au milieu.
C'est là que la machine à écrire montre ses limites. Un modèle autorégressif ne revient pas sur ce qu'il a écrit ; pour corriger un mot au début, il faudrait tout régénérer. La diffusion traite toute la séquence comme modifiable pendant tout le processus. Remplir un trou entre un début et une fin fixés (l'infilling) est une opération naturelle pour la diffusion, et maladroite pour l'autorégressif.
De là vient la formule qui circule sur ces modèles : pas de meilleurs chatbots, mais peut-être de meilleurs éditeurs. Inception Labs, qui commercialise le modèle de diffusion Mercury, le dit autrement : moins une machine à écrire, plus un éditeur qui révise un brouillon entier d'un coup.
Les premiers résultats sur le code donnent du corps à cette intuition. Sur la complétion de code « au milieu » (le fill-in-the-middle, exactement ce qu'on fait en refactorant ou en corrigeant un bug), des modèles de diffusion spécialisés commencent à égaler les meilleurs modèles autorégressifs de taille comparable, et à les dépasser sur les cas multi-lignes. Or patcher, refactorer, corriger, c'est le cœur de la maintenance logicielle, pas de la création.
L'inversion de regard est nette : on a beaucoup parlé de l'IA qui écrit du code à partir de rien. Dans la vie d'une équipe, l'essentiel du travail consiste à faire évoluer du code qui existe déjà. Un outil pensé pour l'édition, et non pour la page blanche, colle bien mieux à cette réalité.
Ce qu'on en fait, concrètement
Trois précautions avant de pivoter une stratégie. La diffusion ne remplace pas l'autorégressif, et Google le dit lui-même : pour la qualité maximale, il recommande Gemma 4 classique plutôt que DiffusionGemma. Sur les benchmarks de raisonnement, l'écart penche nettement vers l'autorégressif.
Les limites sont réelles. La diffusion génère des blocs de longueur fixe, d'où des bricolages pour produire des textes longs. Elle est plus lente sur les longs contextes, car son attention bidirectionnelle se recalcule à chaque passe là où l'autorégressif met en cache. Et le raisonnement en chaîne (« attends, je me suis trompé… ») s'intègre mal à une génération par blocs. Côté agents autonomes, les premières études sont sévères : la vitesse brute ne se traduit pas mécaniquement en meilleure réussite sur les tâches multi-étapes.
Le bon modèle mental traite la diffusion comme une brique spécialisée, pas comme un remplaçant de l'autorégressif : taillée pour l'édition locale rapide, l'infilling et le raffinement, dans des pipelines hybrides où chaque modèle fait ce qu'il sait faire de mieux. DiffusionGemma le fait déjà en interne : de la diffusion à l'intérieur d'un bloc, de l'autorégression entre les blocs.
Les terrains où le gain est tangible aujourd'hui :
- L'autocomplétion et la suggestion d'édition dans l'IDE, où la latence se ressent immédiatement et où la tâche est par nature de l'édition.
- Les workflows agentiques à faible latence : un agent qui enchaîne vingt appels de modèle voit chaque seconde gagnée multipliée. Passer de 3 s à 0,6 s par appel transforme l'expérience.
- L'exécution locale et edge, où la diffusion brille (un seul utilisateur, pas de batching cloud) et où DiffusionGemma tient dans 18 Go de VRAM quantifié.
La question de veille, celle qui dira s'il faut réviser ce jugement : un modèle de diffusion qui gère nativement la longueur variable, supporte un cache efficace sur long contexte, et referme l'écart de raisonnement sous cinq points face à un autorégressif de taille équivalente. Le jour où ces trois cases sont cochées, la conversation change.
La diffusion ne donne pas encore une IA qui pense mieux. Elle ouvre une piste sous-estimée : une IA qui révise, comble et corrige, là où nous avions presque oublié que l'essentiel du travail sur un texte, et sur du code, tient à l'entretien plus qu'à la création.
Sources
- Google DeepMind, DiffusionGemma (modèle ouvert, licence Apache 2.0), annonce de juin 2026.
- Inception Labs, Mercury (modèle de langage à diffusion) — inceptionlabs.ai.
Articles similaires
« Coding is solved » : pourquoi votre entreprise n'a pas encore le droit d'y croire
Définition, bascule « coding is solved » et garde-fous : ce que l'agentic coding change vraiment en entreprise.
GLM-5.2 : le modèle open-weights de Z.ai qui défie les modèles fermés pour agentique coding !
Annoncé mi-juin 2026, GLM-5.2 de Z.ai (ex-Zhipu AI) est un modèle open-weights — MoE, 744 milliards de paramètres, contexte 1M, licence MIT — optimisé pour le codage agentique long-horizon. Specs, benchmarks constructeur, prix, et les réactions d'experts comme Jeremy Howard ou Mat Velloso.
Edge AI : le smartphone comme orchestrateur d'agents
Du copilote au chef d'orchestre : une révolution silencieuse dans nos poches Pendant des années, le smartphone a été notre fenêtre sur le monde numérique : un terminal intelligent, certes, mais fondamentalement passif dans son rapport à l'information. Il affichait, il...
TypeScript : le langage AI-Native par excellence
Quand l'IA choisit son langage de prédilection Il y a quelque chose de fascinant à observer comment l'écosystème du développement logiciel se réorganise autour de l'intelligence artificielle agentique. Parmi tous les signaux que nos équipes ont captés pour les Tech Trend...