Modèles de diffusion
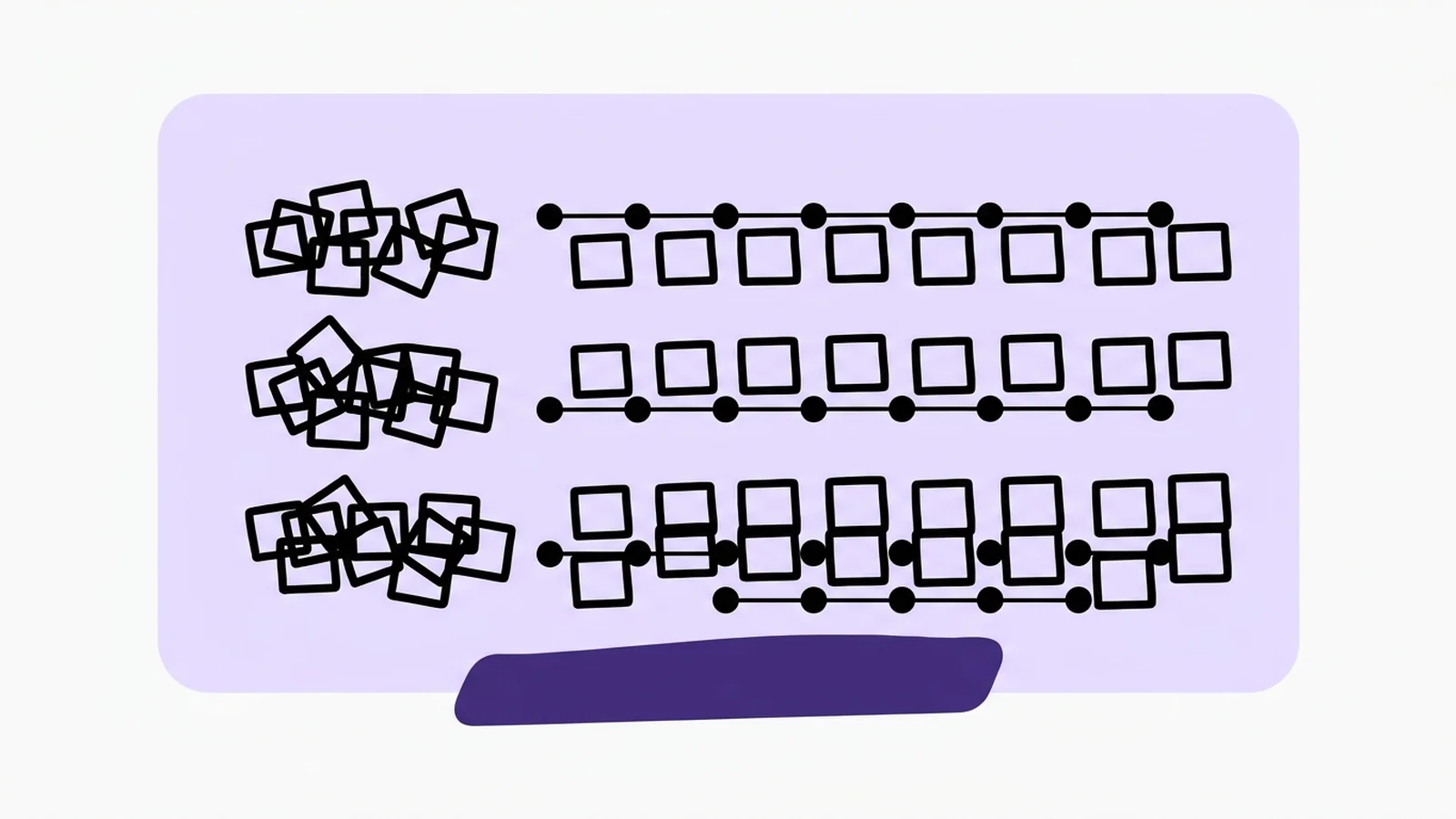
Génération de texte où le modèle raffine tout un bloc par passes successives, au lieu d'écrire token par token comme l'autorégression.
Raffiner un bloc plutôt qu'écrire mot à mot
Les modèles de diffusion appliquent au texte la technique qui a donné les générateurs d'images (DALL·E, Midjourney, Stable Diffusion). Au lieu de prédire le token suivant de gauche à droite, le modèle part d'un brouillon entièrement bruité et le raffine en plusieurs passes, en travaillant sur toute la séquence à la fois. L'attention est bidirectionnelle : chaque mot voit ceux qui le suivent.
Une force pour l'édition, pas la page blanche
Parce que la séquence reste modifiable jusqu'au bout, la diffusion excelle sur les tâches d'édition : reformulation, infilling (combler un trou entre un début et une fin fixés), refactoring et correction de bugs. C'est le cœur de la maintenance logicielle. En juin 2026, Google DeepMind a publié DiffusionGemma (licence Apache 2.0), qui annonce jusqu'à 4 fois plus de tokens par seconde qu'un modèle autorégressif comparable.
Une brique spécialisée, pas un remplaçant
La diffusion reste en retrait sur le raisonnement étape par étape et les longs contextes ; Google recommande Gemma 4 classique pour la qualité maximale. Le bon usage est hybride : la diffusion comme brique d'édition locale rapide et de faible latence (IDE, agents, exécution edge), l'autorégression pour le raisonnement et la conversation.
Questions fréquentes
Quelle différence entre un modèle de diffusion et un modèle autorégressif ?
Un modèle autorégressif écrit le texte token par token, de gauche à droite, sans revenir en arrière. Un modèle de diffusion part d'un bloc bruité et le raffine par passes successives, en gardant toute la séquence modifiable. Il peut donc corriger ses erreurs et combler un trou au milieu.
Les modèles de diffusion vont-ils remplacer les LLM actuels ?
Non, pas à court terme. Ils restent en retrait sur le raisonnement et les longs contextes. Leur intérêt est d'être une brique spécialisée pour l'édition rapide (autocomplétion, infilling, refactoring) dans des pipelines hybrides.